The TT_STR token type for Program Grammar #2 is a subset of a C-language double-quoted string. The string starts with a double-quote and ends with an unescaped double-quote. The quotes are not part of the collected string. The backslash is used as the escape character within the string. (Backslash has no special meaning outside of a string.) The escaped character following the backslash inside the string is treated specially (in the manner of C), as follows:
- \\ (backslash backslash): translates as a single backslash inside the string
- \n (backslash 'n'): translates as a newline character inside the string
- \" (backslash double-quote): translates as a double-quote character inside the string
- anything else (backslash anything-else): translates as backslash anything-else (no change)
Examples (similar to C language strings):
"This is a simple string." "This is line one.\nThis is line two.\nThis is line three.\n" "You can \"quote\" within the string using escaped double-quotes." "Unrecognized escape sequences such as \x and \y appear unchanged." "To get a single backslash, use two, like this: \\ ."
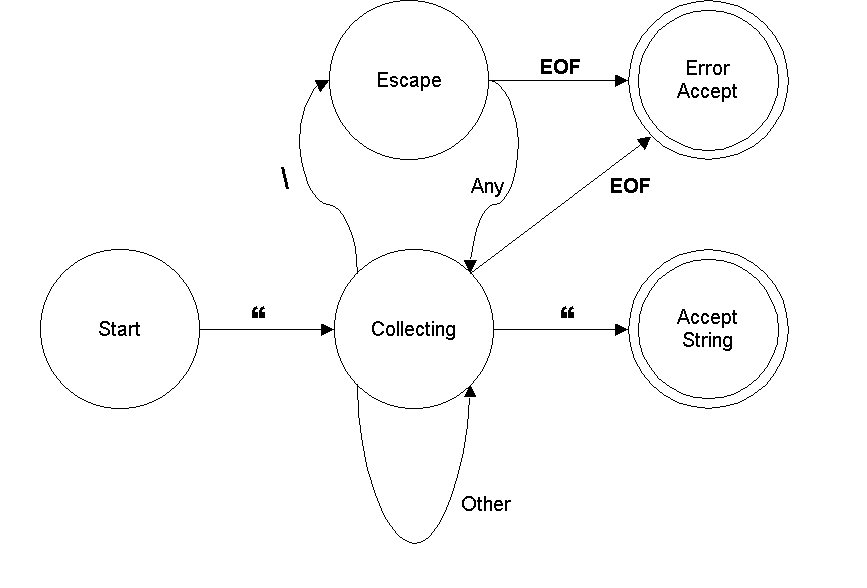
The Deterministic Finite Automaton that recognizes these strings has exactly five states:
- one start state
- one collecting state
- one escape state
- one accept state
- one error-accept state (for when the string hits EOF before finding the closing double-quote)
Starting in the start state, the collecting state is entered upon seeing the first double-quote character. The escape state is entered from the collecting state upon seeing a backslash, and is exited by any following character. (Any character seen in the escape state causes a transition back to the collecting state.) The accept state is entered from the collecting state upon seeing a (second) double-quote. While in the collecting state, all characters except backslash and double-quote cause transitions back to the collecting state; this is where most of the characters are processed.
On seeing EOF in either the collecting or escape state, move to the error-accept state and accept the partial string.
Do not save the opening double-quote in the lexeme for the string.
Inside the DFA, save into the string all characters where state current == next == COLLECTING. Note that this means characters such as real newlines are valid inside strings; strings may span multiple lines in the input stream. (Optional enhancement: Prohibit unescaped newlines inside strings. To insert a raw newline in a string, require that it be preceded by the escape character.)
On the state transition from escape back to collecting, switch on the character seen. This character is the character following the backslash. What you save in the current lexeme for the string depends on what the escaped character is:
IF current-state is ESCAPE and next-state is COLLECTING THEN SWITCH ON character CASE 'n': put a newline in lexeme, break -- newline escape CASE '"': put a double quote in lexeme, break -- double-quote escape CASE '\\': put a backslash in lexeme, break -- backslash escape DEFAULT: -- Unknown escape pair - just put the character and the -- backslash that preceded it into the string unchanged put a backslash in the lexeme put the character in the lexeme END SWITCH END IFWhen the closing double-quote is seen in the collecting state, the Scanner moves to the accepting state, ends the string, and returns a pointer to the string to the Parser, classified as the STRING token type. If the Parser needs to keep a string pointed to by the token, it must make a copy of it, since the Scanner will be overwriting the lexeme buffer when it scans the next token.
Do not save the closing double-quote in the lexeme for the string.
You can try this if you are interested.
If you add one more state to your DFA for strings, you can permit ANSI string contatenation, e.g. the two strings "abc" "def" separated by whitespace would be joined and returned to the Parser as the single string "abcdef" (without the quotes, of course).
Hint: Make the current accepting state for the string non-accepting and have it skip over any (optional) whitespace that follows a string. The character following the whitespace will tell whether another string is present.
The DFA of your Scanner must detect EOF occurring anywhere inside a string (or in an escape sequence), make a transition to an errror-accepting state, and report the improperly-terminated string as a warning or an error. You can treat the string collected so far as junk, returning the JUNK or UNKNOWN token to the parser, or you can return it as a STRING token even though it isn't strictly lexically correct. (Or, you can throw it away.)
Whatever you do, you must detect and report the error; do not put the EOF sentinel into the string, and do not try to keep collecting characters into the string after having seen the EOF. (After EOF there won't be any more characters to put in the string!)
The EOF sentinel must always cause your DFA to move to an accepting state of some kind, since after having seen EOF no other characters can be read from the input stream.