Source program files contain text (characters) that describe the data elements and the processing required to perform some particular processing task.
The form that this textual description takes depends upon the specific language being used. In general, such languages can be divided into two major categories: high-level languages (e.g. Java) and low-level or assembler languages (e.g. Intel assembly language). In either case, the textual program must be converted from text (characters) into the stored-program binary machine code actually used to control the computer's internal circuits.
A compiler is a program that translates high-level source program files (e.g. C++) into binary machine code. A compiler translates high-level statements into machine-level instructions, often requiring many machine-level instructions to perform each high-level program statement. The high-level language is independent of the type of CPU or processor being used.An assembler is a simpler translating program that translates low-level source program files for a specific CPU type into binary machine code. Each machine-level action of the CPU is represented by a single low-level mnemonic textual code. Assembly language coding provides a direct way of controlling the CPU at the machine-code level, without having to remember and write the machine code. The assembler program is specific to the type of CPU being used.
Understanding the assembly process is necessary to understand the translation process of higher level languages into machine code. In many cases, compilers can be told to produce assembly language as an intermediate output file.
In addition to the use of mnemonic codes to represent machine-level instructions, assembly language coding uses symbolic labels to represent memory addresses, rather than having to use actual numbers. When a specific memory location is required for use in an instruction, a symbolic reference to the corresponding label is used. A label can only correspond to a single (low-level) memory address, however, there may be many symbolic references to this label.
The translation of assembly language into machine-code requires that the assembly language file be read twice in a "two-pass" process:
Pass 1: Determining label address locations - read the assembly language code in a first pass, determining the memory location for each instruction and data item. Record the memory addresses of any symbolic labels used in a label table called a symbol table.
Pass 2: Translation to Machine Code - read through the assembly language code a second time. For each instruction, replace any symbolic addresses with their actual memory locations as determined during the first pass, then translate the mnemonic operation and its address into a machine level instruction.
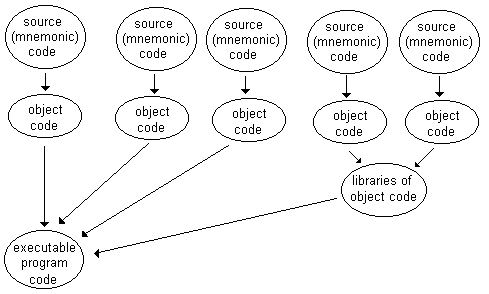
Even once source code has been translated into machine level instructions, there is generally a lot of work that may need to be done before we have a working program.
Most programs are developed in a modular fashion and are composed
of separate pieces (files) of code that have been assembled or
compiled separately into independent machine-code output files,
called object files. Some of these object files may be part of
the program being developed, and others may be available as external
libraries of object code, e.g. various system libraries of object code.
All these separately-produced object files need to be combined into one complete machine-code executable program.
For each independent object file, there is no way to know at compile/assembly time what memory locations are available to store the machine code or where the object file will be in memory with respect to all the other object files used to make up the program. Each object file of machine code is therefore independently produced on the assumption that it is the only code in memory and that it will be placed in memory starting at location zero.
When it comes time to place all the separate object files into memory to create the program, work has to be done to relocate each object file into its own memory region. Each object file except the very first one has to be moved and relocated into a new memory region different from the region in which it was originally compiled/assembled.
All the machine instructions that refer to memory locations as if the module were loaded at location zero will have to be adjusted to refer to memory locations in the region of memory where the object file is actually loaded.
Memory references between object modules have to be resolved: When one piece of code makes a function/subroutine call or memory reference to a location inside another object module, those references have to be resolved into the actual memory locations where the modules end up in memory.
The process of taking separate machine-code object modules and combining them all into a working program is called linking.
To explore the linking process, we will first consider how the Little Man Computer can be expanded to permit handling of functions and subroutines.
A function/subroutine may be called from several different locations in a main program and the subroutine must be able to return to the instruction after whichever instruction called it. Coding a static JMP (jump) instruction in the subroutine does not work to return control from a subroutine back to the main program, since the jump could only return to one place. The jump provides no information as to from where the jump originated. Every call of a function/subroutine needs to record a different return address somewhere so that the subroutine can use the return address to return to the correct place in the calling program.
A function/subroutine call operation must somehow save the memory address of the instruction that occurs immediately after the call. Usually, a special "Subroutine Return" instruction is used to retrieve this saved address and use it to return to from where the subroutine was called. In designing the new LMC CALL instruction, we considered that the return address might be saved in one of several ways:
Support for the use of functions and subroutines necessitated the creation of a new LMC instruction named CALL, used to call functions/subroutines and allow the subroutines to return to the code that placed the CALL.
The original Little Man Computer posed some significant restrictions in implementing an extension that would permit management of subroutines. Specifically:
Only one decimal digit (0) was not used by the original Little Man as a machine-level operation code. This meant that, while it was possible to add an new instruction to call a subroutine, there were no numeric code values left to add a return instruction.
Establishing a method for saving the return address (the location where control should resume after completion of the subroutine) is difficult. The Little Man Computer supplies only a single working register, the Accumulator, and no easy way to use the contents of this register as an address. Furthermore, if the Accumulator were used to hold the return address when a call were made to a subroutine, this would eliminate the possibility of using the Accumulator to pass values to or return values from the subroutine.
The method selected for the extended LMC (called the "sonOfLMC") is to use the unused numeric code 0xy as the CALL xy instruction in a method very similar to the use of 9xy as the JMP xy instruction.
The difference between the CALL xy and JMP xy is that the CALL xy first stores a "return address" trick in the memory location that immediately precedes the location being CALL'ed, i.e. at memory location xy - 1. That "trick" being stored is a JMP instruction that returns to the location physically after the CALL. In other words, the JMP being stored uses the address currently in the Counter when the CALL is being executed.
For CALL xy to work, each subroutine must be coded with a mailbox that is left unused, located immediately before the instruction that is being CALL'd in the subroutine. This unused mailbox will receive the JMP trick put there by the CALL instruction.
When a subroutine has completed its task and wishes to return to the "calling" routine, it must JMP to this trick location (that is to the mailbox containing the JMP put there by the CALL that entered the subroutine). The JMP to the JMP will cause control to return to the statement physically following the original CALL.
Passing argument values to a subroutine and retrieving them in the subroutine as parameters involves some of the same memory location problems as maintaining the subroutine return address. Where do you put the arguments before calling a subroutine? Where do you put the return value(s) before returning from a subroutine? The actual method used depends upon the use of a protocol agreed to by both the calling and the called routines.
The method for passing parameter values to a subroutine is left unspecified by the structure of this extended version of the LMC. Parameter passing is a protocol to be decided upon between the two routines involved, but, in general, information sharing (passing argument values to the subroutine and returning result values to the calling routine) is normally achieved either through single values passed in the LMC calculator, or through the use of global labelled memory locations.
The main routine will typically copy subroutine argument values into global variables in the subroutine before calling the subroutine, and the subroutine will store return values in the same (or other) global variables before returning. This method assumes that, if separately assembled (or compiled modules are used, there will be some method for identifying these shared, labelled memory locations.
As has been already noted, modules (or "subroutines") are generally assembled (or compiled) from source files into separate object files. This results in three major problems:
Lost Public Labels - As a source file is translated into binary machine code by the assembler program, all the label address information is lost. Machine code has no label information. Object files containing machine code must therefore keep a separate table of Public Labels for use by the linker in identifying important address locations inside the module. Not all labels in the source code may be public. Local variable labels do not need to be preserved in the Public Label table. The label that is the start of a subroutine must be put in the Public Label table so that other programs can call the subroutine.
Calls to External Routines - Calls to routines not included with the source can not have their actual memory addresses filled in to the machine code, since those addresses are not known at the time the source translation is done. The object file must keep a list of these "unresolved external references" for later resolution by the linker program when the linker knows where in memory these external routines have been placed. The object file must include the name of the called external routine and the location within the calling routine where the external routine is called, so that the linker knows what memory locations to fix when the actual memory addresses are known.
Relocatable Address References - Instructions or data that were translated to machine code based on the assumption that the routine would be loaded starting at a specific address, usually zero, need to be modified if the routine is loaded at a different address. Not all machine code needs to be modified, only instructions or data that refer to addresses inside the routine need to be adjusted. The object file must contain a table of all locations containing addresses that must be relocated to reflect the actual load address used for the routine.
As a result of the above three problems, object files typically contain three tables to accompany the machine code. This means an object file contains four parts: machine code plus three tables:
a Public Label table containing a list of all Public Labels defined within the module, and their corresponding mailbox (memory) addresses. "Public" labels are labels that should be made available to other modules. All other labels are private, local labels that are not visible to other modules. (Private labels may or may not be saved inside the object module. Some object modules only save private label information if you specifically ask for it for debugging purposes.)
an External Reference table containing a list of all mailbox addresses that make references to public labels defined in other modules, plus the name of the actual label being referenced.
a Relocation Address table containing a list of all the addresses containing instructions that include address references to addresses within the module (based on the false assumption that the module would be loaded starting at address 00). All relocatable memory address references will need to be adjusted to reflect the true memory address values once the true starting address of the module has been established by the linker.
All the addresses in the above three tables are themselves subject to relocation if the subroutine is loaded at a non-zero address.
Suppose we want a simple program that outputs pairs of numbers: the first number of each pair output will be a count value starting at 000 and stopping before reaching a MAX of 010; the second number of each pair will be double the value of the first number. In order to allow the user time to read the numbers output, the program will pause after each output for a certain amount of time (performing some time wasting loop). (Note that the program stops before reaching the MAX value; the MAX value is not output.)
We will code this as 3 separate source files: a MAIN program and two subroutines Pause() and Dble(). Here is the pseudocode for the three modules:
// *** MAIN program ***
int count = 1
int max = 10
do {
output count
call Pause()
call Dble(count)
count += 1
} while ( count < max );
stop
// *** PAUSE subroutine ***
subroutine Pause() {
int count = 0
do {
count -= 1
} while ( count != 0 );
}
// *** DBLE subroutine ***
subroutine Dble(arg) {
output arg+arg
call Pause()
}
Here are the three modules, translated in to LMC assembly language and then assembled into three object files:
| MAIN Mnemonic Source Code | MAIN Object File - machine code and tables | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
MAIN
Repeat LDA Count ; output count
OUT
CALL Pause
LDA Count
STO Arg ; store subroutine argument
CALL Dble
LDA Count ; count += 1
ADD One
STO Count
SUB Max ; while ( count < max )
SKP
JMP Repeat
HLT
Count DAT 000 ; local symbol (not Public)
One DAT 001 ; local symbol (not Public)
Max DAT 010 ; local symbol (not Public)
PUB MAIN ; MAIN is a Public Label
Pause EXT ; Pause is an External Ref.
Arg EXT ; Arg is an External Ref.
Dble EXT ; Dble is an External Ref.
|
00: 113 01: 600 02: 000 03: 113 04: 200 05: 000 06: 113 07: 314 08: 213 09: 415 10: 802 11: 900 12: 700 13: 000 14: 001 15: 010 |
|
|||||||||||||||
| Pause Mnemonic Source Code | Pause Object File - machine code and tables | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
DAT ; CALL return address
Pause LDA Count ; start of subroutine
SUB One
STO Count
SKZ ; while ( count != 0 )
JMP Pause
JMP Pause-1
Count DAT 000 ; local symbol (not Public)
One DAT 001 ; local symbol (not Public)
PUB Pause ; Pause is a Public Label
|
00: 000 01: 107 02: 408 03: 207 04: 801 05: 901 06: 900 07: 000 08: 001 |
|
|||||||||||
| Dble Mnemonic Source Code | Dble Object File - machine code and tables | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
Arg DAT ; input argument to Dble
DAT ; CALL return address
Dble LDA Arg ; start of subroutine
ADD Arg ; double the input value
OUT
CALL Pause
JMP Dble-1
PUB Arg ; Arg is a Public Label
PUB Dble ; Dble is a Public Label
Pause EXT ; Pause is an External Ref.
|
00: 000 01: 000 02: 100 03: 300 04: 600 05: 000 06: 901 |
|
|||||||||||||
As is always the case with separately created modules, the main program and each subroutine have been assembled into object modules and machine code as if none of the other code existed:
If we collect all the Public Labels from all modules, we have Public Labels for MAIN, Pause, Arg, and Dble. If we collect all the External References from all modules, we have External References for Pause, Arg, and Dble. Every External Reference can be matched with a Public Label, which means all the modules are present.
Combining multiple object files together to form a single executable program (often stored as a file) is the job of a program called a link-editor, or "Linker". The link process can be viewed as a sequence of five steps:
Copy the numeric codes from all object files into sequentially contiguous locations, keeping track of the address used for each routine's new memory start address. Typically the first object file is loaded starting at address zero and the other object files go at higher memory locations.
The tables in each object file were built assuming the object file was loaded at location zero. Since we have just loaded many subroutines at non-zero start addresses, we have to fix the addresses in the tables for each routine to reflect the new location of the subroutine in memory. Adjust the memory location specifications in the Public Label, External Reference, and Relocatable Address Location tables in each object file by adding the new memory load address of the subroutine to each location specification in each table.
Having loaded all the subroutines into memory, we now know exactly where in memory each public symbol resides and we can go back and fix up the external reference information in all the loaded routines. Adjust all external reference memory locations by adding the actual public address of the externally referenced public symbol to the address portion of instruction at that location.
The code in each object file was built assuming that the object file was loaded at location zero. Since we have just loaded many subroutines at non-zero start addresses, we have to fix each relocatable instruction in each subroutine to account for the move to a new location. Using the relocatable address locations table in each object file, adjust all relocatable address locations in each subroutine by adding the new memory address of the corresponding routine to the address operand at each relocatable location.
The program is now "linked" and ready to execute as a unit. Save the modified numeric code to an executable file.
We will expand each of the above five steps by running through this process with the previously generated object files:
00: 113 01: 600 02: 000 03: 113 04: 200 05: 000 06: 113 07: 314 08: 213 |
09: 415 10: 802 11: 900 12: 700 13: 000 14: 001 15: 010 |
17: 107 18: 408 19: 207 20: 801 21: 901 22: 900 23: 000 24: 001 |
25: 000 26: 000 27: 100 28: 300 29: 600 30: 000 31: 901 |
The main program loaded at zero; Pause loaded starting at memory address 16; Dble loaded starting at memory address 25. The linker builds a table indicating the actual location where each subroutine was loaded in memory:
| Routine | Assembled to load at: | Actually Loaded At: |
|---|---|---|
| main routine | 00 | 00 |
| Pause subroutine | 00 | 16 |
| Dble subroutine | 00 | 25 |
The linker will use these new memory locations to "relocate" addresses inside each subroutine, below.
The linker examines all the Public Label tables in all the object files and ensures that every public label is unique; a public/global label cannot refer to two different memory locations. In our example, the linker records four unique public labels - MAIN, Pause, Dble, and Arg - with no conflicts. (The other labels that were in the original source files were not made public and so are not visible to the linker.)
Since the Public Label tables were built assuming that every object file loaded at location zero, the linker has to fix the addresses in the public tables to account for the new memory locations of each subroutine. The linker adds the new load address of the corresponding subroutine to the address of each public label in that subroutine's object file:
| Public Label | Modified Location (based on load address) |
|---|---|
| Pause (in the Pause object file loaded at 16) | 01 17 (=01+16) |
| Arg (in the Dble object file loaded at 25) | 00 25 (=00+25) |
| Dble (in the Dble object file loaded at 25) | 02 27 (=02+25) |
This modified Public Label table now contains the correct memory location of every public label. The linker will use these locations to satisfy references to external symbols, below.
The linker examines all the external reference tables from all the object files and ensures that every external reference has a match in some Public Label table. If a match isn't found, then some object file is referring to some label for which there is no corresponding public label and the program cannot be linked. (Perhaps someone forgot to include a subroutine in the link process?)
In our example, the linker sees references to three external labels - Pause, Dble, and Arg - and all three have entries in some Public Label table.
Since the external reference tables were built assuming that every object file loaded at location zero, the linker has to fix the addresses in the tables to account for the actual memory locations of each subroutine. The linker adds the load address of the corresponding subroutine to the address of each external reference in that subroutine's object file:
The external reference table from the Pause object file is empty. If there were any references, we would add the new memory location where Pause was loaded (memory location 16) to every entry in the table.
We have loaded the Dble subroutine at memory location 25, which means that all the locations in the Dble external reference table must be modified by the addition of the Dble subroutine's load address (25) before they can be used. The external reference table from the Dble object file says that Dble CALLs the Pause subroutine - an external reference - at location 05. The linker adds 25 to that value in the External Reference table:
| External Reference for Dble | Modified Location (+25) |
|---|---|
| Pause | 05 30 (=05+25) |
The linker examines all the relocatable address locations tables in all the object files. Since the relocatable address locations tables were built assuming that every object file loaded at location zero, the linker has to fix the tables to account for the actual memory locations of each subroutine. The linker adds the load address of the corresponding subroutine to the address of each relocatable location in that subroutine's object file:
The main routine was loaded at location zero, so even though it has a relocatable address locations table, the linker would simply add zero to every address, resulting in no change to the table.
| For the Pause subroutine (loaded
starting at 16) Modified Relocatable Address Locations (+16) |
|---|
| 01 17, 02 18, 03 19, 05 21, 06 22 |
| For the Dble subroutine (loaded
starting at 25) Modified Relocatable Address Locations (+25) |
|---|
| 02 27, 03 28, 06 31 |
Now, the relocatable address locations have been adjusted to compensate for the actual load address of the subroutine.
Having loaded all the subroutines into memory, we now know exactly where in memory each public symbol resides and we can go back and fix up the unresolved external reference information in all the loaded routines:
| External Reference for MAIN | Location |
|---|---|
| Pause | 02 |
| Arg | 04 |
| Dble | 05 |
Using the above table and the modified Public Label table, the instructions in (mailbox) addresses 02, 04, and 05 are changed by adding to the current contents the value of the actual public location addresses from the (modified) Public Label table:
|
CALL Pause
STO Arg CALL Dble |
02: 000 017 (17 is Pause in the Public Label table)
04: 200 225 (25 is Arg in the Public Label table) 05: 000 027 (27 is Dble in the Public Label table) |
Since the Pause object file contains no external references, no modifications are required inside Pause to fill in the addresses for unresolved external references.
The (modified) external reference table from the Dble object file is used to identify which locations within the Dble subroutine refer to external symbols whose location weren't known when Dble was assembled into object code. The (modified) external reference table for Dble tells the linker which memory locations inside Dble need to be fixed to refer to which external symbols:
| External Reference for Dble | Modified Location (+25) |
|---|---|
| Pause | 05 30 (=05+25) |
The (modified) external reference table says that location 30 refers to Pause, so the linker looks up the real location of Pause in the (modified) Public Label table (17) and adds that value to Dble memory location 30:
| CALL Pause | 30: 000 017 (17 is Pause in the Public Label table) |
All external references have now been updated to refer to their correct memory locations.
Finally, the instructions at the locations identified by the (modified) relocatable address locations table inside each object file must be adjusted by the actual location where that specific subroutine was loaded. The contents of memory at the addresses specified in the (modified) relocation address locations table must be modified to compensate for the actual load address of the subroutine:
Since the main program's object file was assembled to load at location zero and was actually loaded at location zero, no address modifications are required for main. (Adding zero to every relocatable address doesn't change it.)
The Pause subroutine was coded to load at location zero but was actually loaded at location 16. The linker adds 16 to every relocatable address in the modified relocatable address locations table for Pause:
| For the range of mailboxes of the Pause subroutine | |
|---|---|
| Relocatable address locations: 17, 18, 19, 21, 22 | |
| Original values from the Pause object file |
Relocated instructions based on module load at 16 |
01: 107 02: 408 03: 207 05: 901 06: 900 |
17: 123 (=07+16) 18: 424 (=08+16) 19: 223 (=07+16) 21: 917 (=01+16) 22: 916 (=00+16) |
The Dble subroutine was coded to load at location zero but was actually loaded at location 25. The linker adds 25 to every relocatable address in the modified relocatable address locations table for Dble:
| For the range of mailboxes of the Dble subroutine | |
|---|---|
| Relocatable address locations: 27, 28, 31 | |
| Original values from the Dble object file |
Relocated instructions based on module load at 25 |
02: 100 03: 300 06: 901 |
27: 100 125 (=00+25) 28: 300 325 (=00+25) 31: 901 926 (=01+25) |
This completes the relocation of all the instructions in all the subroutines.
The linker has resolved all external references and relocated all relocatable code. At this point all address operands should be correct and the combined block of code properly executable. The code is output to an executable file, ready for loading and execution by the system.